 Log in
Log in

| 1 | ||
| 1 | ||
| 1 | ||
| 1 | ||
| 1 |
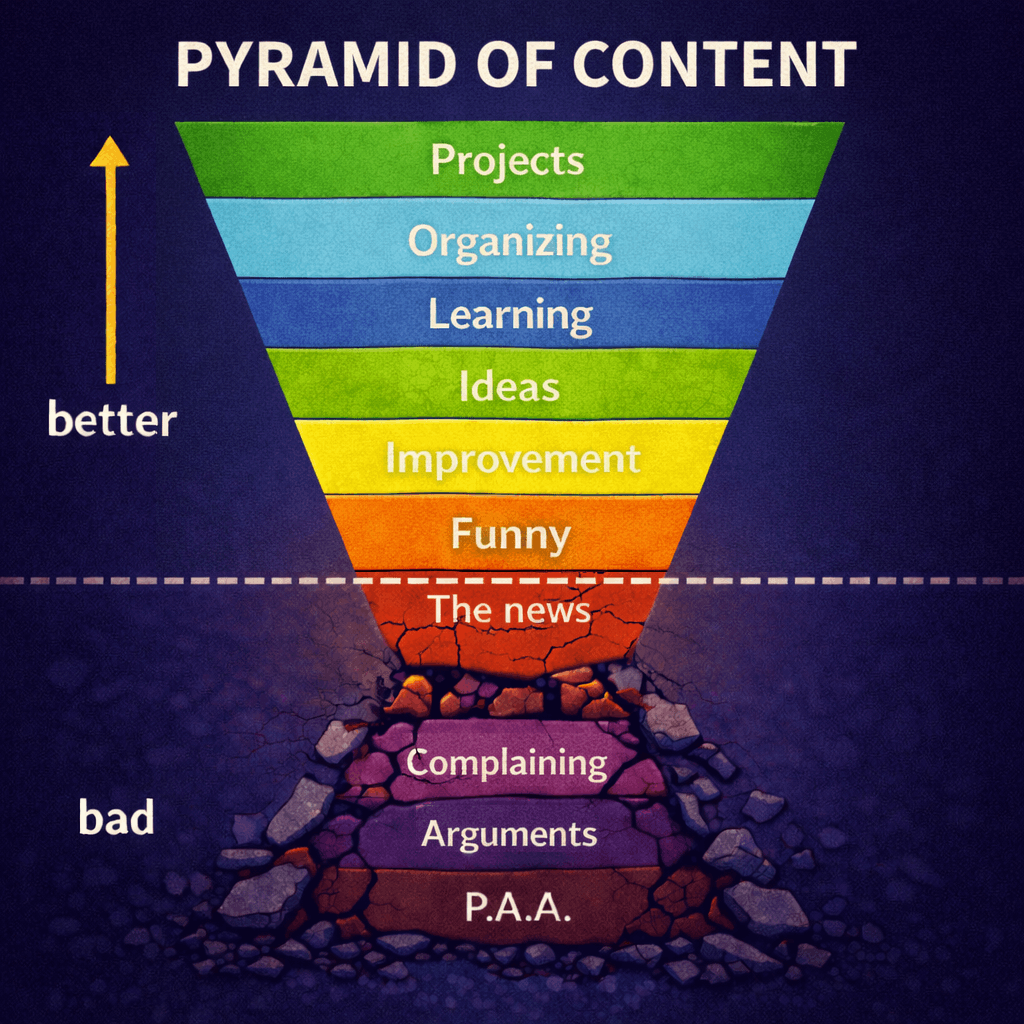
In this thread we share our number one goal for the day. Just one goal.
After that we also do a check-in some time in the middle to share how it is coming along. It helps if you pre-determine a time. And then also share how it went at the end. This is modled after what we do at game jams.
My goal is to implement a structure for an AI I've wanted to build since about a year ago. It uses swappable sub-matrixes (by referrence) for customizable models without memory bloat. I plan to do a check in at 6pm and share the results at 11pm.
Let me know your top goal for the day. Be sure to tell us how it went. What are you working on?


My goal was to get to the point where I felt good enough to do a hardware renewal on my old laptop. And I managed to make it happen. New CMOS batt, main batt, palmrest, better screen. With it's new and more lightweight OS, it should continue to serve me well for many more years.
I did that with an old Acer Laptop, it ran Ubuntu just fine. But for the cost of repairing it, I could have bought a $150 Acer new laptop.
That would have been fine, if the new laptop wasn't saying
"Oh but you just can't survive without an online account!"
"Here's where you give us permission to track data on everything you do or say, everywhere you go, and everything you view, just click Next"
"Here's our beautiful new AI! Use it! You should use it! You're going to use it! NO you can't delete it USE IT OR ELSE"
and all the other bullshit Windows has become well known for.
Instead, I could take the super tough 3rd gen i7 that served me well for many years, and it can help me learn new tricks.
I chose the new tricks.
Want to know why RAM prices are so high? The priority for RAM companies is AI Data Centers, causing a shortage for the rest of us.
IFIFY:
...is Controligarchy AI Data Centers...
Things might be different if the public were involved in our own destiny, woken-source culture wars weren't a problem, and ZZZtheyZZZ weren't so hellbent on global tyranny and domination.
Both the Right-Wing and Left-Wing belong to the same bird.
And it's got one helluva big beak
I'm nearly finished reading some self help book
I like this idea and projects-oriented productive direction.
Not sure if it will work. If I'm busy then I don't have time to report my progress, and I'm not sure anyone would care or be able to help.
Yesterday I finished fireproofing a basement, so today I'm taking a break, cleaning up, catching up (never ends), likely attending a freedom meeting this eve, and will be back at other work tomorrow and beyond.
Check in:
I got started on this later than I wanted. It's not like this is the only thing I'm doing today. But I'm pretty happy with what I have. I've implemented these super-matracies / sub-matracies for about the seventh time now. But now I think I have a keeper.
The important thing that seperates this time from earlier stabs is I now have a way of saving these things in a way that leverages the matrix by reference system. In prior times of playing with this concept these were in memory only. This run is using C++. My matrix operations are naive self-codes for now but I should be able to swap in google XLA soon so I can get that sweet cpu/gpu interop.
The other nice thing about this run is that I did my standard supermatrix_matmul different. In prior implementations it assumed the sub-matrices were always aligned so you could do matmul on them directly and accumulate their result into a target to get the desired result. Now the shortest named version of matmul in the library for supermatracies can be unaligned. For example I can have supermatrices A and B and submatrices c,d,e such that A=[[c,d]] and B = [[c,e]] with c being 10x8 and d and e being 10x2. That gives me an equivelent matracies that is 10x10, which can be multiplied in the classic case. In prior implementation I've done this couldn't multiply because we'd be multiplying a 10x8 by a 10x2 at some point.
I'm about to add the faster block aligned function in a second. The above example of needing to worry about alignment is untypical for the intended usecase. The point of the system is to be able to extend and AI with larger matracies. I came up with this idea when LoRAs were not a thing and it was my solution to that problem and I still think it has strengths. If you are going to extend an existing network with expansions then your blocks are all going to line up by design anyway.
The other goal to get done before the second (and last) check in is getting back-propagation in. IDK why I've built my own back-propagation systems before but I always stop this project before testing and verifying it with this exact system. On some of these earlier stabs I had even implemented my own auto-grad systems from scratch, multiple times, but back-propagation on super-matracies has always been where things stop despite significant pencil and paper work on it in the past. So if I break through that wall that will make me happy.
Closing checkin:
I'd say it all went well. This is something I've wanted to build for about a year. I got hung up on something silly at the end. But first what went well.
Since the last check in I got rid of all allocations inside the operations part of the code. Now inputs and output memory are fed into all operations. I switched the matrix multiplication to my prefered orientation, which is transposed matrix multiplication. It's what a lot of programs use because it's faster, the code is more understandable, and it's conceptually easier to reason about. Mathemiticians just defined matrix multiplication backwards. I now do have the block aligned implementation available so it should run faster.
What ended up being more of a slog that it should have been is tokenizing. It's the computer I'm on. It's just fighting me on getting set up. Huggingface AutoTokenizer is really easy once you have Huggingface installed right. But basically I decided I'm going to make a simple spam classifier with it. And the question came up, what tokenizer do I use. And I decided the answer is all of them. Since the whole point of this system is transfer learning I figured I should train it on multiple tokenization schemes. The idea is to have modules you can tack onto a model anytime something changes that would throw it off. A change of input, change in the intended application, or a change in knowledge you want it to have. Then you train all the cases. The common things to learn end up in the common blocks (hopefully), and the unique things to learn end up in the unique blocks.